Look Who's Talking: Turn Your Spreadsheets Into Hyperlocal Audio News
What would it sound like if a spreadsheet could talk?
Well, a recent experiment by Project CITRUS has given us one answer to that question.
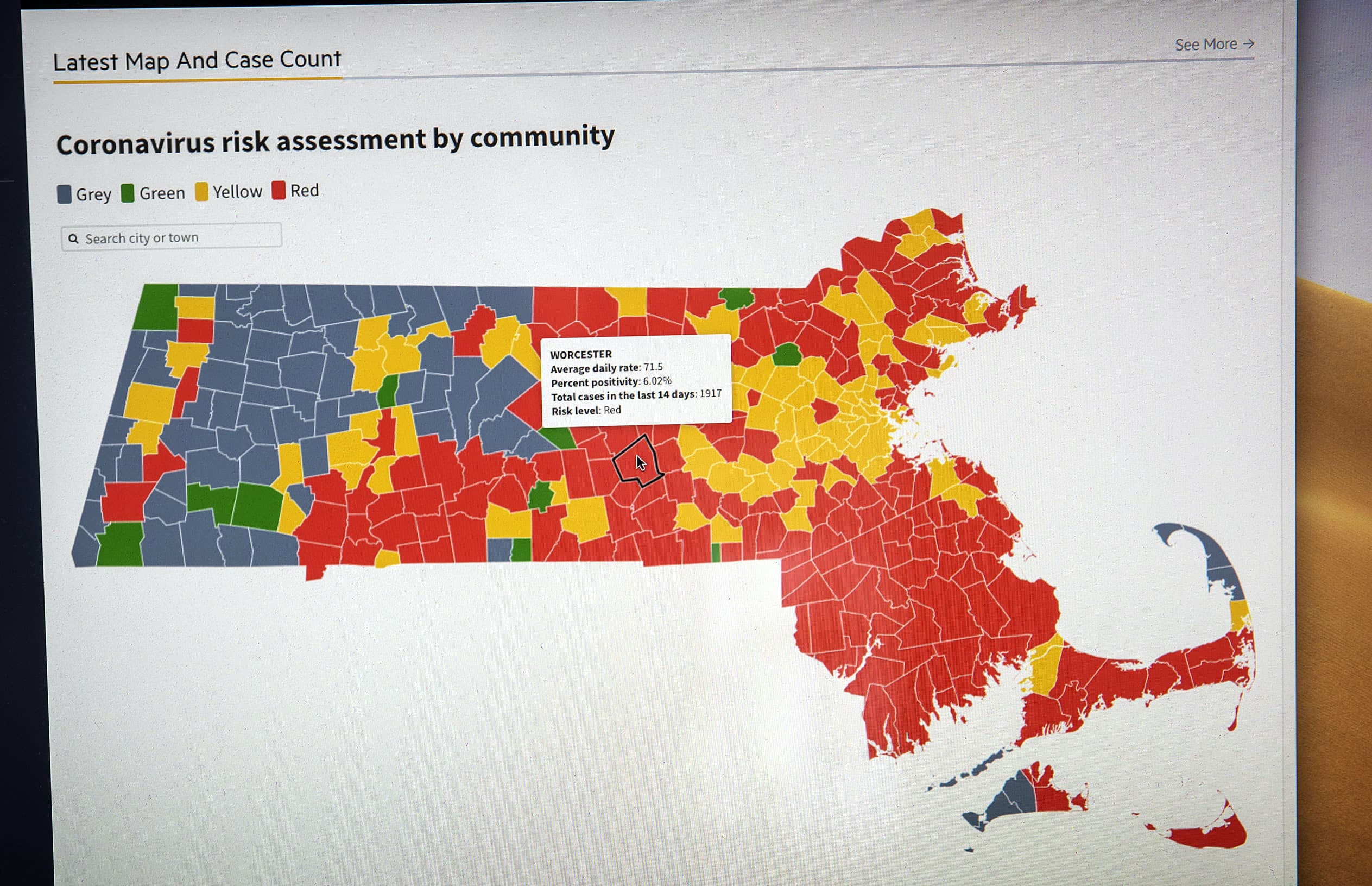
Here's the backstory: Since last March, the WBUR newsroom has been painstakingly tracking coronavirus data released by the Massachusetts Department of Public Health. We've been assembling our own database and manually adding the state data into various Google Sheets. Those sheets in turn power WBUR's coronavirus charts and maps, which contextualize key health metrics at the state, county and city/town level in an easy-to-digest format.
Data like this is of course best suited for a visual consumption. But we also saw an opportunity to use AI to turn our growing coronavirus database into short, useful audio content.
One of the many lessons we've learned from making Coronavirus, Briefly — WBUR's daily coronavirus microcast — is that data does not typically make for the most compelling listening experience. Over time, data in an audio-only context starts to go in one ear and out the other. (Imagine if someone was trying to share multiple phone numbers with you, but you had no pen and paper on which to write them down.) Because of this, we stopped incorporating daily statewide coronavirus data at the tail end of the show (a standard practice for several months) and instead started pointing listeners to WBUR.org for more information.
On the other hand, hearing the data about your specific community — where you go to the grocery store, where your kids go to school — seemed much more compelling. But, needless to say, we couldn't ask an already-swamped host or reporter to record a bespoke update for all 351 cities and towns in Massachusetts, every single week.
So the problem looked like this:
- How can we generate an MP3 containing a short, city/town-specific coronavirus data update, without burdening WBUR staff?
- How can we then serve that short, hyperlocal update to only the listeners for whom it is relevant and useful?
Step 1: The Architecture
We first needed to whiteboard out a solution to see if this was even technologically possible. After some research, testing and debate, we settled on a necessarily — but not overly — complex toolset.
To address the first part of our problem, a text-to-speech service was the obvious choice.
We ultimately picked Amazon Polly because we already have an Amazon Web Services account, we're familiar with the AWS CLI, it's inexpensive and — the most vital criteria for any audio producer — it sounds good. AWS recently rolled out a "Newscaster" speaking style for Polly, which felt much more appropriate as the lead-in for a news microcast.
WBUR already uses Megaphone for audio delivery, so that too was a no-brainer. And fortunately for us, Megaphone clients can add dynamic, non-advertising pre-rolls (aka "Promos") to their audio. Most important, there are APIs for these services — automating this otherwise grueling process.
Step 2: Building The Pipeline
As mentioned above, our town-by-town coronavirus data is scrupulously stored in a Google Sheet. So it's of course trivial to turn that into a CSV for easier consumption. A Python script then loops over the data, row by row, where each row represents a single city or town in Massachusetts. With each iteration, we create a basic script template, plugging town data into variable slots. We then send that final text up to Polly.
Once Polly is done, we start the second step: sending the audio up to Megaphone to create a preroll at the beginning of Coronavirus, Briefly.
Step 3: Geotargeting
Megaphone allows for four levels of geotargeting: country, state, designated market area (DMA) and ZIP code. The first three are far too large for solving our problem. The last is too granular — Boston alone is home to dozens of ZIP codes — but we can still work with it.
The first step was to find a file that maps town names to one or more ZIP codes. If you can't, you might just have to make you own. Though, fair warning:
- Some ZIPs straddle several municipalities (looking at you, Chestnut Hill!)
- Several small towns will occasionally share a single ZIP; other times, a particularly tiny town won't have a post office at all, and will use several ZIPs from its neighbors.
- There can be lots of ambiguity around town names and spellings. ("Foxboro" vs. "Foxborough," for instance.)
If you can iron out these discrepancies and live with the remaining outliers, you should be able to geotarget your listeners with a decent degree of accuracy.
Step 4: Putting It All Together
Finally, we return to our Python loop and add some logic that maps each town name to one or more ZIP codes (whenever possible). After every promo is created and every file uploaded, Megaphone is ready to serve geotargeted pre-rolls on any episode of Coronavirus, Briefly we choose.
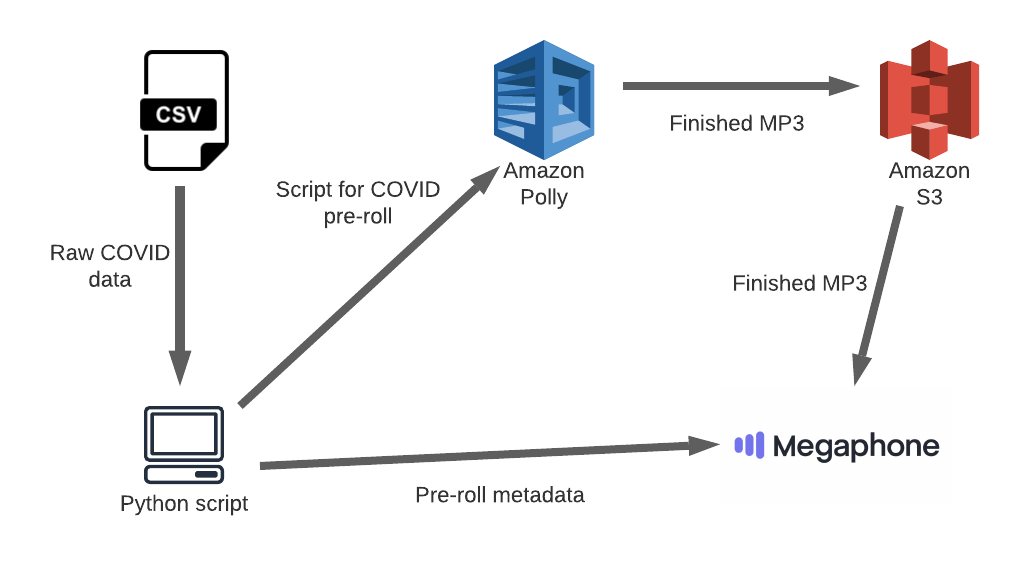
If Megaphone sees that the listener is in the ZIP code of 02478, it knows to prepend the episode with the audio file of coronavirus data for Belmont. Here's an example of what that sounds like all put together:
This is an area we're eager to continue examining: How can WBUR use AI, geotargeting and dynamic insertion to augment on-demand audio, and reach listeners with "hyperlocal" news that keeps them informed about their community?
How We Selected A Speaking Style
As with any experiment involving a synthetic voice, we (both white, cisgender men) wanted to weigh all the available options — and our own implicit biases — before creating our text-to-speech pre-rolls.
AWS offers nine "English (US)" voices for Polly — but only two, named "Matthew" and "Joanna," are compatible with its "Newscaster" style. (Both are gendered in the AWS documentation.) We debated these two options among our small team, and then sought more feedback from a wider group.
A majority gravitated toward Matthew's slightly more lifelike intonations and conversational delivery. However for some, Matthew sounded almost too good — "in the uncanny valley," as one co-worker put it. Joanna sounded perfectly suitable as well (if a little more robotic in comparison). And pre-empting our host, Franziska Monahan, with another female voice sounded less jarring.
We ultimately chose Matthew. And unfortunately, no matter how much time we spent debating, there wasn't an objectively "correct" choice.
One more interesting data point: When we tested out some pre-rolls in Spanish, both of us — we are poor, at best, Spanish speakers — thought it sounded amazing, and perfectly human. But a co-worker who is a native speaker immediately called it out, saying, "You can tell it's a robot but it definitely got the point across." They also pointed out that the word "COVID" sounded like it was spoken in English.
This discussion was highly educational, and once again reminded us of the well-documented links between voice AI and reinforcement of gender and racial biases. Interestingly, there is work being done on gender-neutral voices. In this case, we certainly would have benefitted from having a more inclusive range of speaking styles, of equal quality, to choose from.
Tipping Our Cap
Much of the inspiration for this experiment came from a recent project by the Lede Lab at The Washington Post. During the 2020 election, the Post used its Heliograf technology to create localized text-to-speech updates about race results. Those updates were then stitched onto news podcasts like "Post Reports" and "The Daily 202's Big Idea" as pre-rolls. For example, if you were listening in Massachusetts that week, you'd hear an update on the state's congressional contests, or on how far Joe Biden's lead in the Commonwealth had extended.
NPR's recent rollout of Consider This — the first podcast to use ad technology to serve a local news segment based on a listener's DMA — also helped us realize this concept's potential. Here again, instead of a "national/local" mix of content, we saw an opening to attempt a "local/even more local" content mix via similar technological means. (Full disclosure: WBUR is among the 12 public radio stations participating in the launch of Consider This, and the CITRUS team co-produces the Boston-region segment.)
If this project inspired you, AWS offers extremely affordable pricing for Polly usage, even if you use the costlier "neural" text-to-speech option, as we did. We've also posted some demo code on GitHub. If you decide to try this out, let us know on Twitter. We'd love to hear how it goes!

